
개발 공부를 함에 있어서 처음부터 매우 자주 나오는 단골 주제인 값 형식 vs 창조 형식.
예전 글에서도 몇 번 다뤘지만, 간단하게만 다루고 넘어갔기 때문에 이번 기회에 해당 주제에 관련된 것을 최대한 많이 정리 해보도록 하겠다.
값 형식 (Value Type)
값형은 변수에 값을 직접 저장한다.

가장 먼저 배우는 방식의 데이터 형식이기도 하다.
int, float, double과 같은 기본 자료형부터 시작해서
구조체 struct도 이러한 값 형식의 저장 방식을 쓴다.
깊은 복사 (Deep Copy)
변수가 실제 데이터를 보유하게 되며, 이 데이터를 다른 변수에 할당하거나 전달할 때 값을 복사한다.

이러한 방식의 복사를 깊은 복사라고 한다.
이 때 하나의 변수를 수정해도 다른 변수의 데이터에 전혀 영향을 주지 않게 된다.
struct MyStruct
{
public int Value;
}
MyStruct struct1 = new MyStruct();
struct1.Value = 10;
MyStruct struct2 = struct1; // struct2는 struct1의 값 복사
struct2.Value = 20;
Console.WriteLine(struct1.Value); // 출력 결과: 10
참조 형식 (Reference Type)
참조 형식의 변수는 데이터의 값이 아닌 데이터에 대한 참조 (메모리 주소)를 저장한다.
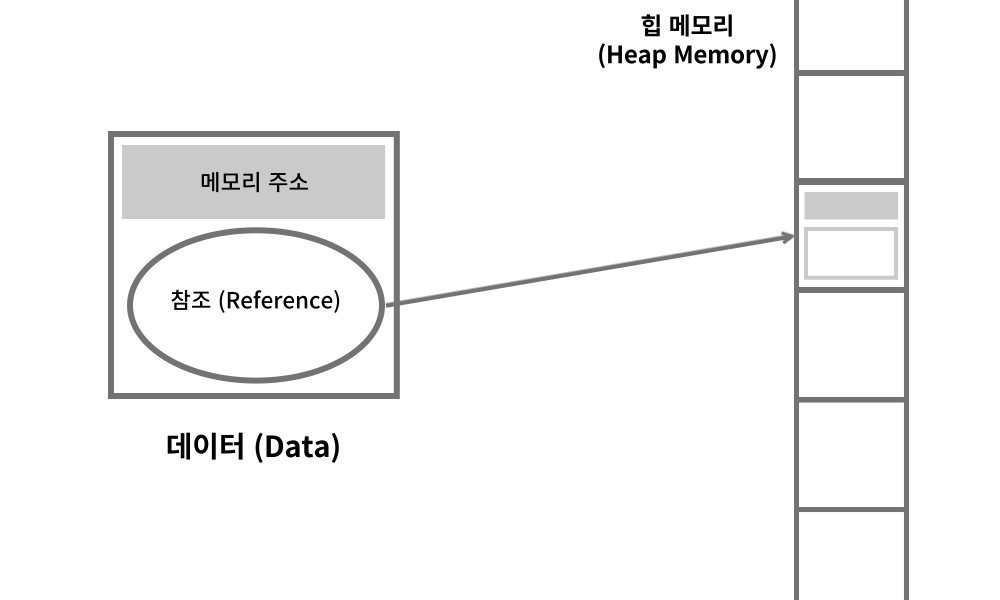
클래스, 배열, 인터페이스 등이 참조형에 해당한다.
변수가 실제 데이터를 가리키는 참조를 갖게 되며, 할당을 하는 순간 데이터의 주소를 가져가게 된다.
얕은 복사 (Shallow Copy)
참조 형식의 변수를 다른 변수에 할당하거나 전달할 때 값이 아닌 참조가 복사된다.
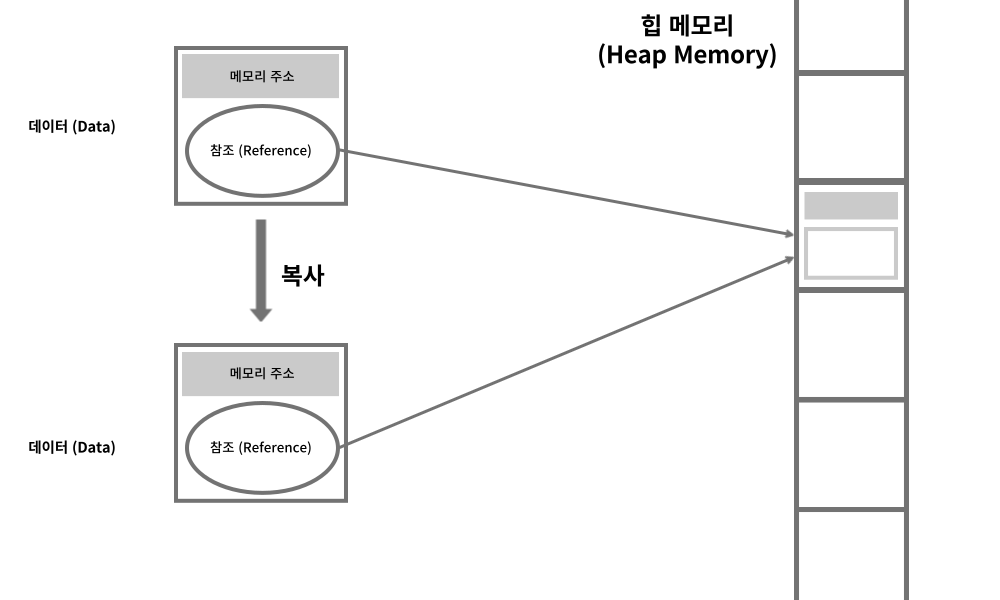
이러한 방식의 복사를 얕은 복사 (Shallow Copy)라고 한다.
이 때 변수 내의 값을 수정하면, 동일한 데이터를 가리키고 있는 다른 변수도 같은 값을 가리키기 때문에 다른 변수에 영향을 줄 수 있다.
class MyClass
{
public int Value;
}
MyClass obj1 = new MyClass();
obj1.Value = 10;
MyClass obj2 = obj1; // obj2는 obj1과 동일한 객체를 참조
obj2.Value = 20;
Console.WriteLine(obj1.Value); // 출력 결과: 20
값 형식 vs 참조 형식
값 형식과 참조 형식은 데이터가 저장되는 방식도 다를 뿐더러 저장되는 위치마저 다르다.
값 형식은 스택 메모리에 저장되고, 참조 형식은 힙 메모리에 저장된다.
해당 내용에 대해서는 이전 게시글에 한 번 다룬 적이 있으니 한 번 읽어보자.
 https://seoksii.tistory.com/9#62bcac3e-ff19-4cd1-a6e5-2f4c57a89887
https://seoksii.tistory.com/9#62bcac3e-ff19-4cd1-a6e5-2f4c57a89887
스택 메모리의 장점은 단순하고 효율적인 구조이기 때문에 할당과 해제에 드는 오버헤드가 크지 않다는 것이다.
그래서 값 형식의 데이터를 다루는 것이 약간 더 가볍다.
단점으로는 컴파일 시점에 할당하려는 메모리 크기를 미리 알아야 스택으로부터 메모리를 할당받을 수 있다는 점이고, 다른 객체에서 스택 메모리의 변수를 접근하기가 힘들다는 것이다.
힙 메모리의 장점은 런타임에 메모리 할당을 받을 수 있고, 타 객체로부터 접근이 쉽다는 것이다.
단점은 반대로 할당 및 해제를 하는데에 오버헤드가 든다는 것이다.
오버헤드가 왜 발생하냐면 힙은 임의의 주소에 메모리를 할당하고 해제하기 때문에 메모리 할당을 할 때 순차적인 탐색이 필요하다.
이 순차적인 탐색을 위해 참조 타입 객체들은 기본적으로 타입 객체 포인터와 동기화 블록 인덱스라는 두 개의 추가 필드가 할당 된다.
또한 더이상 사용하지 않는 데이터를 탐지하기 위해 참조 카운팅 (Referecence Counting)을 해야하기 때문에 할당과 해제 두 과정에 모두 오버헤드가 존재하는 것이다.
박싱과 언박싱
박싱과 언박싱은 기본적으로 값 형식과 참조 형식 사이의 변환을 의미한다.
박싱은 값형 변수를 참조 형식으로 바꾸는 과정이고, 언박싱은 이렇게 박싱된 객체를 다시 값형으로 변환하는 과정이다.
만능 도구처럼 보일 수 있겠지만 주의가 필요하다.
박싱 과정에서 메모리 오버헤드가 발생할 수 있고, 언박싱의 경우 런타임에 타입 검사를 해야하기 때문에 시간이 더 걸린다.
따라서 너무 자주 쓰게 되면 성능 저하를 일으킬 수 있으니 주의해야 한다.
객체를 박싱해서 힙에 들어갈 때 가비지 컬렉터가 이를 가비지로 판단하여 치워버리는 골때리는 상황이 발생할 수 있는 것은 덤.
using System;
class Program
{
static void Main()
{
// 값형
int x = 10;
int y = x;
y = 20;
Console.WriteLine("x: " + x); // 출력 결과: 10
Console.WriteLine("y: " + y); // 출력 결과: 20
// 참조형
int[] arr1 = new int[] { 1, 2, 3 };
int[] arr2 = arr1;
arr2[0] = 4;
Console.WriteLine("arr1[0]: " + arr1[0]); // 출력 결과: 4
Console.WriteLine("arr2[0]: " + arr2[0]); // 출력 결과: 4
// 박싱과 언박싱
int num1 = 10;
object obj = num1; // 박싱
int num2 = (int)obj; // 언박싱
Console.WriteLine("num1: " + num1); // 출력 결과: 10
Console.WriteLine("num2: " + num2); // 출력 결과: 10
}
}
List<> 형태에서 박싱은 다음과 같이 할 수 있다.
List<object> myList = new List<object>();
// 박싱: 값 형식을 참조 형식으로 변환하여 리스트에 추가
int intValue = 10;
myList.Add(intValue); // int를 object로 박싱하여 추가
float floatValue = 3.14f;
myList.Add(floatValue); // float를 object로 박싱하여 추가
// 언박싱: 참조 형식을 값 형식으로 변환하여 사용
int value1 = (int)myList[0]; // object를 int로 언박싱
float value2 = (float)myList[1]; // object를 float로 언박싱
Uploaded by N2T
'개발 > Unity 내일배움캠프 TIL' 카테고리의 다른 글
| C# StringBuilder 정리 (0) | 2023.08.28 |
|---|---|
| C# LINQ 간단 정리 (0) | 2023.08.25 |
| C# Sort() 메서드 다루기 (0) | 2023.08.23 |
| C# DataTable 간단 사용법 (0) | 2023.08.22 |
| C# 연산자 오버로딩과 인덱서(Indexer) (0) | 2023.08.21 |



